





When companies first deploy AI agents, the default assumption is: pick the best available model, point all your agents at it, ship. This works for the first month and then becomes the largest line item on your cloud bill. The math doesn't add up at scale — and more importantly, it's bad engineering. The most capable model is rarely the right model for most tasks.

 By Admin
By AdminOne Model Doesn't Fit Every Task: The Three-Tier Strategy Inside Crewmate
Crewmate ships with six models out of the box and a per-agent selector. Here's why, and how it should be used.
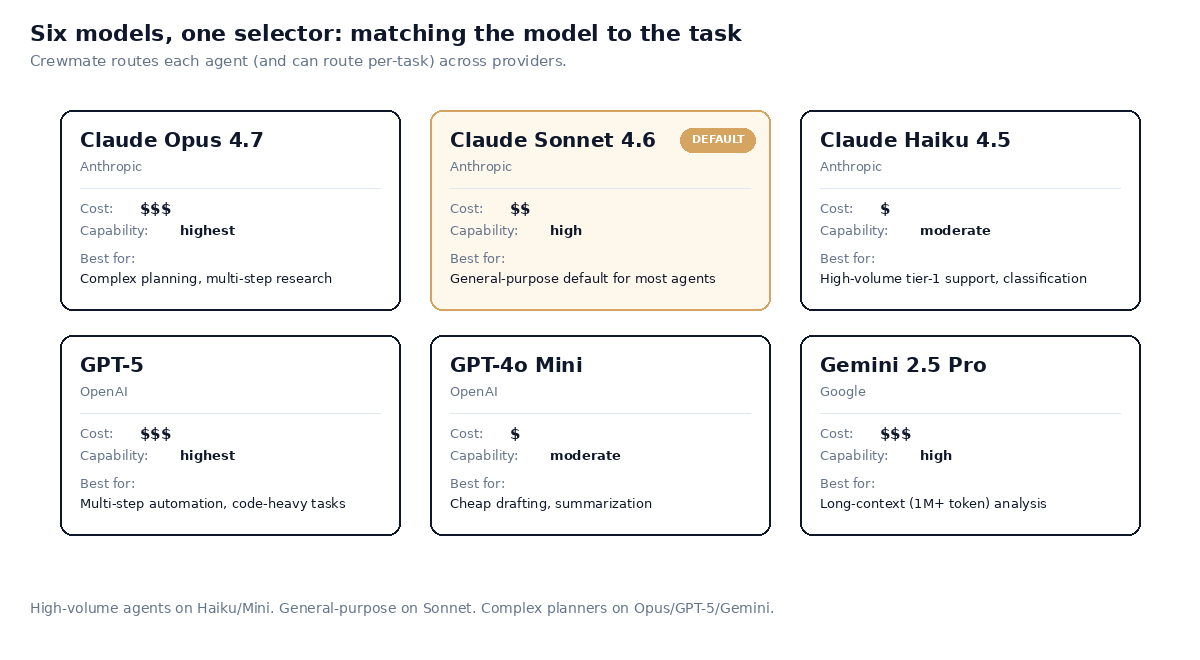
Six models across three providers. Cost and capability vary. The selector lets you match each agent to the right one.
The Cost vs Capability Trade-off
Every frontier model is on a curve. More capable models cost more per token. The difference can be 10x or more between the cheapest and most expensive in the same family. At small volumes, the cost difference doesn't matter — you spend pennies either way. At a meaningful scale (hundreds of thousands of agent runs per month, which is normal for a small SaaS), the difference is the difference between profit and loss.
The trick is that capability isn't a single dimension. A heavyweight model is much better at multi-step planning, complex reasoning, and ambiguous tasks. It's only marginally better at simple classification, drafting, or extraction. So the question for any given agent is: does this agent's work actually require the heavyweight capabilities, or am I overpaying for capacity I'm not using?
Three tiers, roughly
The decision becomes manageable if you think about it as three tiers, regardless of provider:
- Top tier (Opus, GPT-5, Gemini 2.5 Pro): Complex planning, multi-step research, ambiguous tasks where the model needs to figure out what to do, not just how. Best for: agents doing genuine knowledge work that requires reasoning across many sources.
- Middle tier (Sonnet, the default in Crewmate): General-purpose, good at most tasks, reasonable cost. Best for: agents handling structured workflows, drafting, customer-facing conversations with moderate complexity. This is where most agents should live.
- Lower tier (Haiku, GPT-4o Mini): Fast, cheap, narrow. Best for: high-volume tier-1 work, classification, summarization, anything where the task is well-defined and the model just needs to execute. Surprisingly capable for the price.
How does the Selector work?
In Crewmate, every agent has a model selector. The default is Sonnet 4.6 — the right choice for most agents. Owners or managers can change it per agent: route the Support agent to Haiku for cost, route the Strategic Planning agent to Opus for capability. The selector also supports per-task routing inside more advanced workflows, though most teams don't need that complexity in their first year.
The selector is also where you make cross-provider bets. Most agents work fine on Anthropic models, but if your team is OpenAI-aligned for compliance reasons, or if you've validated that GPT-5 outperforms on your specific workload, you can route there. Crewmate is genuinely model-agnostic — none of the workspace logic depends on a particular provider.
Real-world Cost Reduction
A representative example. A mid-size SaaS deploys five agents on Crewmate: Support, Sales SDR, Docs maintainer, Internal reporting, Content drafting. Default configuration puts all five on Sonnet. Their monthly token bill, at moderate usage, runs about $400.
After a month, they audit. Their Support agent handles mostly tier-1 questions — well-defined, repetitive, low-judgment work. They route it to Haiku. Their reporting agent generates the same weekly metrics summary — they route it to Haiku too. Their content drafting agent benefits from Sonnet's writing quality, they keep it. Their Sales SDR is mid-complexity, they keep it on Sonnet. Their Docs agent is generating internal content with light judgment, Sonnet stays.
Monthly token bill after the audit: about $190. Same agents. Same work. About 52% cost reduction. The Support agent's quality doesn't drop noticeably — the work was always within Haiku's capability.
When to Upgrade, not Downgrade?
The other direction matters too. If you're getting persistent agent failures — bad drafts, missed reasoning steps, the agent visibly struggling — try routing that agent up before you assume the agent design is wrong. A Sonnet agent that fails at a planning-heavy task often succeeds on Opus. The cost goes up, but if the agent's output goes from "frustrating" to "reliable," the math usually still works.
This is the calibration mindset that production AI rewards. Stop assuming the model is fixed. Treat it as one of the configuration knobs you tune like any other.
The strategic point
Companies that treat model choice as a one-time decision will look back in two years and realize they overspent meaningfully on tokens for routine work, or underspent on capability for hard work. Companies that treat model choice as a per-agent configuration question will operate substantially more efficiently and get better outcomes.
The cost difference compounds over the lifetime of a deployment. So does the quality difference. Both matter, in different directions, for different agents. The selector is the tool. The strategy is using it.